SECS/GEM Troubleshooting: Common Issues and Solutions
Key Takeaway
Most SECS/GEM failures come from configuration mismatch, incomplete state handling, missing event reports, or unstable reconnect logic. A structured troubleshooting checklist can reduce integration time and prevent repeated fab acceptance failures.
Connection problems
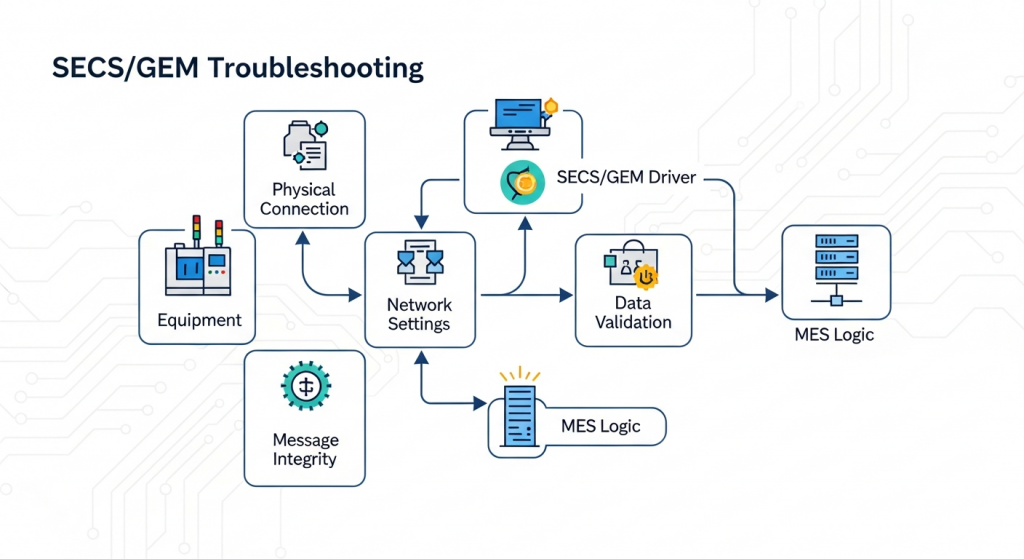
The first class of SECS/GEM issues is connection setup. HSMS active/passive mode, IP address, port, device ID, T3/T5/T6/T7/T8 timeout settings, and firewall rules must match between host and equipment. If the TCP connection opens but SELECT fails, check HSMS role configuration and device ID first. If SELECT succeeds but communication later freezes, inspect timeout handling and linktest behavior.
Online and control-state issues
GEM requires a clear equipment communication and control-state model. Many tools can connect but never transition cleanly to the expected online remote state. This blocks recipe download, remote start, or event collection. Verify that the equipment reports state changes consistently and that the host does not assume remote control before the tool has completed the required transition.
Missing events and reports
Another common problem is event configuration. The host may subscribe to collection events, but the tool returns incomplete reports or variable IDs that do not match the interface document. Build a simple event matrix: event name, CEID, expected variables, trigger condition, and sample message. Test each event with a repeatable equipment action.
Alarm and recipe issues
Alarm IDs should be stable and meaningful. If the same fault appears under different IDs, FDC and maintenance workflows become unreliable. Recipe problems usually come from inconsistent naming, checksum mismatch, permission control, or unsupported process-program format. Always test upload, download, compare, select, and delete flows separately.
Debugging checklist
- Capture raw message logs on both host and equipment sides.
- Verify HSMS mode, port, device ID, and timeout values.
- Test S1F13/S1F14 connection and online transition before advanced functions.
- Validate every CEID and report variable against the interface document.
- Simulate reconnect, equipment reboot, host restart, and network interruption.
SECS/GEM troubleshooting is fastest when teams separate transport, state model, events, alarms, and recipe services instead of treating every failure as a generic communication problem.
读完这篇,下一步可以很具体
获取一份产线 AI 评估,看看 NeuroBox E3200 / SECS/GEM 怎么接到您的设备。
把设备类型、当前数据接口、工艺目标或良率问题发给我们。工程团队会先判断适合 VM、R2R、Smart DOE、EIP 还是能源优化,再给出下一步建议。
- 适合晶圆厂、设备商、工艺/设备/自动化团队
- 可从 SECS/GEM、Modbus、PLC、CSV/历史数据开始
- 不需要先提交机密 recipe 或客户图纸
Discover how MST deploys AI across semiconductor design, manufacturing, and beyond.

