半导体设备边缘AI vs 云端AI:2026年工厂该怎么选?
核心结论
半导体产线的AI应该部署在设备旁的边缘节点,而不是云端——因为FDC报警需要毫秒级响应、工艺数据不能出厂、云端延迟导致R2R控制失效。迈烁集芯NeuroBox E3200S采用纯边缘架构,所有推理在本地完成,数据不出产线,同时支持模型从云端下发更新。
2026年,每一家半导体工厂的管理层都面临同一个问题:工厂AI究竟应该跑在设备旁的边缘节点,还是部署在云端数据中心?这个问题表面上是IT架构选型,本质上是生产安全、响应速度与竞争优势的战略抉择。本文从延迟、数据安全、网络可靠性、硬件成本和实际应用场景五大维度,系统梳理边缘AI与云端AI的差异,帮助工厂技术决策者做出最合适的选择。
一、半导体AI的延迟要求:为什么云端根本跑不起来
在讨论边缘还是云端之前,必须先搞清楚半导体工艺对AI响应时间的要求有多苛刻。这不是一个可以妥协的参数,它直接决定了AI系统是否真正有效。
三类核心应用的延迟基准
半导体产线上的AI应用,按响应时间要求大致分为三档:
- 故障检测与分类(FDC):响应时间 <100毫秒。设备异常信号(如等离子体阻抗突变、气体流量漂移、腔室压力波动)必须在100毫秒内触发报警并启动保护动作。超过这个窗口,晶圆可能已经受损,甚至造成设备腔室污染,一批次损失动辄数百万元。
- 虚拟量测(VM):响应时间 <10秒。VM通过传感器数据预测晶圆测量结果,替代或减少实物量测。每片晶圆在离开设备前10秒内必须拿到VM预测值,否则无法决定是否放行或返工,产线节拍被打断。
- Run-to-Run控制(R2R):响应时间 <60秒。每批次结束后,R2R系统根据上一批次的实测与VM数据,动态调整下一批次的工艺配方参数(如刻蚀时间、温度补偿量)。60秒的窗口已经是极限——产线不会等待超过一分钟才能开始下一批。
云端的物理极限
即使采用专线连接,工厂到公有云数据中心的往返延迟(RTT)通常在20~80毫秒之间,加上数据序列化、队列等待、模型推理和结果返回,端到端延迟通常超过200毫秒,且存在不可预测的抖动(jitter)。这意味着:
- FDC场景:云端延迟直接超标,报警永远慢半拍,保护动作形同虚设。
- VM场景:90%以上情况勉强达标,但10%的超时就足以让产线操作员手动干预,增加人为误差。
- R2R场景:云端理论上可行,但网络抖动导致控制参数更新不稳定,批次间一致性变差。
结论非常清晰:FDC和VM场景,云端AI从技术上就不可行;R2R场景,云端AI在稳定性上存在系统性风险。
二、数据安全:晶圆厂的工艺数据为什么绝对不能出厂
半导体制造是全球竞争最激烈的行业之一,工艺数据是核心竞争资产。一条成熟工艺节点的量产配方,背后是数年研发投入和数千批次的工程优化,其价值不亚于任何专利。
数据出厂的四大风险
- 知识产权泄露:工艺配方(Recipe)、传感器信号特征、缺陷模式分布,都是高度敏感的IP。一旦上传云端,即使是加密传输,也面临中间人攻击、云服务商内部人员风险,以及各国数据监管合规要求(如中国《数据安全法》对重要数据出境的限制)。
- 客户保密协议(NDA):代工厂(Foundry)为客户(Fabless)生产芯片时,客户工艺数据属于高度机密。任何数据出厂都可能违反NDA,面临巨额违约赔偿和客户流失。
- 监管合规:部分军工、航天、汽车级芯片产线受到出口管制和数据本地化法规约束,明确禁止工艺数据传输至境外或第三方服务器。
- 竞争情报风险:即使单条数据看似无害,大量传感器时序数据经过AI分析,可以反推出工艺窗口、设备状态、良率水平,构成有价值的竞争情报。
边缘AI的数据主权优势
纯边缘部署意味着所有原始传感器数据、工艺参数和推理结果永远留在产线本地。云端如果参与,只接收经过脱敏处理的聚合统计数据(如设备健康评分、良率趋势)或更新后的模型权重文件,而非原始工艺数据。这是当前头部晶圆厂唯一能接受的数据安全架构。
三、网络可靠性:产线断网了AI还能跑吗?
半导体产线是7×24小时连续生产环境,任何非计划停机都意味着直接经济损失。2025年,某国内8英寸厂因为云端AI服务网络中断,导致FDC系统离线4小时,直接损失超过200片晶圆,事后复盘将其列为”不可接受的单点故障”。
网络中断的真实概率
即使是企业级专线,年可用性通常为99.9%(即年中断时间约8.7小时)。对于全年8760小时连续运行的半导体产线,这意味着AI系统每年至少有几次完全失效窗口。云服务商的SLA通常是99.95%~99.99%,听起来很高,但对零容忍的晶圆厂来说远远不够。
边缘AI的离线韧性
部署在设备旁的边缘节点,与网络完全解耦。网络中断时,边缘AI继续本地推理、本地报警、本地控制,产线无感知。当网络恢复后,边缘节点将离线期间产生的数据批量同步至云端,不丢失任何历史记录。这种”离线优先”(Offline-First)架构是半导体工厂AI的黄金标准。
四、边缘AI的硬件:GPU边缘服务器 vs 普通工控机
很多工厂误以为”边缘AI”就是在设备旁放一台普通工控机跑Python脚本。这个认知是错误的。现代半导体AI对边缘硬件提出了严苛要求。
工控机的局限
传统工业PC(IPC)通常配备Intel Core或Xeon CPU,无GPU加速。运行简单阈值判断没问题,但面对深度学习推理任务(如卷积神经网络做缺陷分类、LSTM做时序预测),CPU推理速度比GPU慢10~100倍,根本无法满足FDC的100毫秒延迟要求。
GPU边缘服务器的核心规格
专为半导体产线设计的AI边缘服务器,需要具备以下条件:
- 工业级GPU:NVIDIA Jetson Orin或Tesla T4级别,提供INT8/FP16加速推理能力,推理延迟降至毫秒级。
- 防尘防震设计:半导体厂房洁净室环境对散热设计、电磁屏蔽有特殊要求,消费级服务器不适用。
- 高可靠存储:工业级SSD,支持掉电保护(Power Loss Protection),避免断电导致数据损坏。
- 多协议接口:同时支持SECS/GEM、OPC-UA、Modbus等半导体工业通信协议,直连设备控制器。
- 热冗余设计:双电源、RAID存储,确保单点故障不影响推理连续性。
五、云端AI的真正优势:不可替代的三个场景
正视云端的局限,并不意味着全盘否定云端AI的价值。在以下三个场景中,云端AI有边缘节点无法替代的优势。
1. 模型训练与迭代
训练一个新的FDC模型或VM模型,需要处理数TB的历史数据,运行数百个训练周期,消耗大量GPU算力。这个过程不需要实时性,可以在云端(或私有云/本地AI服务器)离线完成,训练好的模型再下发到边缘节点。云端提供弹性算力,按需扩展,避免在工厂本地采购闲置的训练算力。
2. 跨站点协同与全局优化
拥有多个生产基地的半导体企业(如拥有上海、西安、成都三个厂区),需要在全局视角下比较各站点的良率差异、设备健康趋势,协同调度产能。这类跨站点数据汇聚与分析,天然适合在云端进行,边缘节点没有全局视图。
3. 数字孪生与仿真
工艺仿真、设备数字孪生模型的构建和运行,通常需要强大的计算资源和完整的工厂历史数据。云端提供充足的算力和存储,是构建厂级数字孪生的理想平台,其仿真结果再反哺边缘侧的控制策略。
六、混合架构:边缘推理 + 云端训练的最佳实践
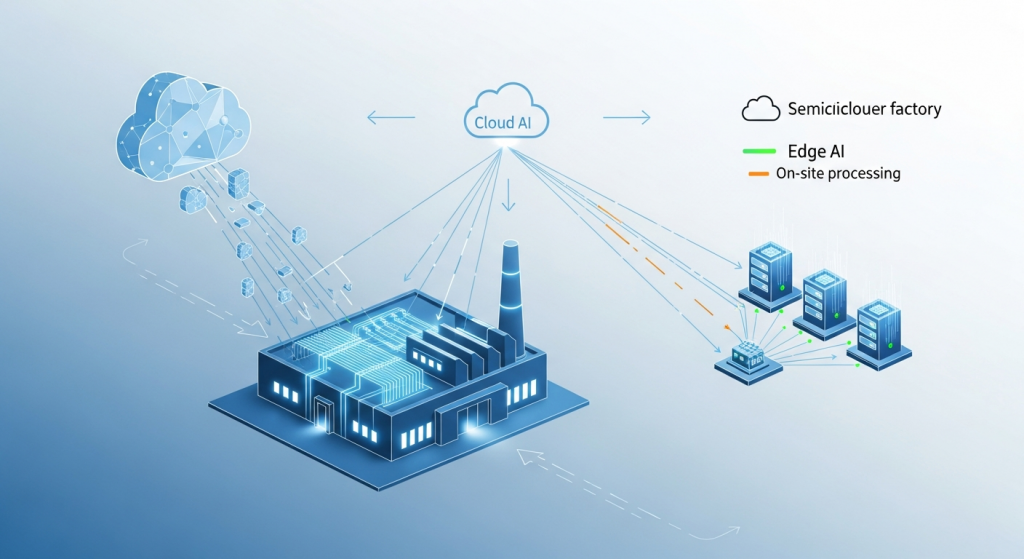
2026年头部晶圆厂的主流选择,既不是纯边缘也不是纯云端,而是分层混合架构。理解这个架构,是AI部署决策的关键。
三层架构模型
- 设备层(L1):边缘推理节点。每台或每组设备旁部署一个GPU边缘服务器,负责实时数据采集、FDC推理、VM计算、R2R控制指令输出。所有原始数据和推理结果存储在本地,不上传。
- 厂区层(L2):本地AI服务器。整个厂区部署一台或多台高性能AI服务器,负责汇聚各设备边缘节点的聚合数据,进行厂区级良率分析、预测维护调度、工艺漂移监控。可以跑增量学习(Incremental Learning),将新数据持续融入模型。
- 企业层(L3):云端平台。接收来自各厂区L2的脱敏统计数据,进行跨站点对比分析、全局模型训练、数字孪生运行。训练好的新模型通过安全通道下发至L1边缘节点,完成模型更新闭环。
数据流向设计原则
在这个架构中,数据流向是单向的:原始工艺数据只在L1本地留存,经过聚合和脱敏后才能向上流动。模型权重文件从L3向下分发至L1。这个设计同时满足了实时性、数据安全和全局优化三个目标。
七、5G在半导体工厂的角色与局限
5G专网在半导体工厂中越来越受到关注。5G的低延迟(理论上1毫秒)和高带宽,是否能让云端AI重新具备可行性?答案是:部分场景有效,但无法替代边缘推理。
5G的实际贡献
5G工厂专网(Private 5G)可以将设备到厂区边缘服务器的无线传输延迟压缩至5毫秒以内,大幅提升L1与L2之间的数据同步速度。对于AGV调度、视觉检测图像传输、设备移动端操作等场景,5G显著提升了响应速度。
5G无法解决的问题
5G只解决了”最后一公里”的无线传输问题,无法消除从工厂到云端数据中心的广域网延迟。FDC的100毫秒要求,即使5G接入也需要边缘节点本地完成推理,5G只是让数据更快到达边缘节点,而不是更快到达云端。此外,5G专网建设成本较高,洁净室内部署还面临信号穿透和电磁干扰挑战。
八、不同场景选择指南
基于以上分析,我们给出五大典型应用场景的架构选择建议:
| 应用场景 | 响应要求 | 推荐架构 | 原因说明 |
|---|---|---|---|
| 故障检测与分类(FDC) | <100毫秒 | 纯边缘 | 云端延迟无法满足;数据敏感,不可出厂;断网必须继续运行 |
| 虚拟量测(VM) | <10秒 | 边缘推理为主,云端辅助训练 | 推理必须在本地;模型可在云端训练后下发;历史数据可脱敏上传 |
| Run-to-Run控制(R2R) | <60秒 | 混合(边缘执行 + 云端优化) | 控制指令由边缘本地计算;全局最优参数可由云端协同推荐 |
| 预测维护(PdM) | 小时级~天级 | 混合(L2本地分析 + 云端跨站点) | 单机维护预测在本地;跨设备、跨站点故障模式比对需云端 |
| 工艺优化与DOE | 批次间(非实时) | 云端为主,边缘执行 | 优化计算不需要实时性;需要大算力和历史数据;结果下发边缘执行 |
九、NeuroBox E3200S边缘架构详解
迈烁集芯(MST)NeuroBox E3200S是专为半导体产线在线AI设计的边缘推理系统,完整体现了上述混合架构的设计原则。
硬件平台
NeuroBox E3200S采用工业级GPU计算模块,配备NVIDIA高性能推理加速器,支持INT8量化推理,FDC推理延迟低于20毫秒,VM计算延迟低于3秒,均远优于行业要求。系统采用无风扇被动散热或正压洁净散热设计,满足半导体厂房洁净室等级要求(Class 1000至Class 10000均有对应规格)。双电源热冗余,RAID-1本地存储,确保硬件层面的高可用性。
软件架构
NeuroBox E3200S的软件栈分为四层:
- 设备连接层:原生支持SECS/GEM II(E5/E30/E37/E40标准)、OPC-UA、EtherNet/IP、Modbus TCP/RTU,可直连主流半导体设备控制器(如TEL、LAM、AMAT、Tokyo Electron等设备的标准接口),无需二次开发网关。
- 实时推理层:内置FDC引擎、VM引擎、R2R控制引擎,均运行在本地GPU上。FDC引擎支持多变量统计过程控制(MSPC)与深度学习异常检测双模式,可根据工艺特点灵活切换。
- 数据管理层:本地时序数据库存储原始传感器数据,保留周期可配置(默认90天)。数据脱敏模块在数据上传前自动过滤敏感字段,确保合规。
- 模型管理层:支持通过安全加密通道从云端接收新模型版本,本地灰度验证后自动切换,整个更新过程不中断推理服务,零停机更新。
与云端平台的协同
NeuroBox E3200S原生集成MST云端平台(MST Cloud),实现完整的边缘-云端协同闭环:边缘节点将聚合指标(非原始数据)上报云端,云端进行跨设备、跨站点分析,训练更新模型后通过加密通道下发至边缘节点。整个流程满足数据不出厂的安全要求,同时享受云端大算力带来的模型持续进化能力。
十、实际部署案例数据
以下数据来自NeuroBox E3200S在国内某12英寸量产产线的实际部署结果,该产线涵盖刻蚀、薄膜沉积、CMP三个工艺模块,共部署12套边缘节点。
FDC性能提升
- 误报率(False Positive Rate)从部署前的每日平均18次降至3次,降幅83%,大幅减少了操作员不必要的人工干预。
- 漏报率(False Negative Rate)从1.2%降至0.15%,真实设备异常的捕获率提升至99.85%。
- FDC报警到产线保护动作的端到端延迟:平均22毫秒,最差情况68毫秒,远优于100毫秒要求。
VM准确率与节拍
- CMP模块研磨后厚度的VM预测精度(1-sigma)达到0.8Å,与实际量测值吻合率99.2%。
- VM计算平均耗时1.8秒,最大4.2秒,满足产线节拍要求,量测机台使用频率降低40%,台机有效产出提升。
R2R控制效果
- 刻蚀模块CD均匀性(Uniformity)从±3.2nm改善至±1.6nm,工艺能力指数(Cpk)从1.12提升至1.68。
- R2R参数更新平均耗时38秒,全部在批次间隔内完成,产线节拍零影响。
系统可用性
- 12套边缘节点年度综合可用性达到99.97%,折合年中断时间约2.6小时,且所有中断均为计划内维护窗口。
- 期间网络中断事件共发生4次,合计中断时长约11小时,期间边缘AI全程独立运行,产线无感知,零晶圆损失。
结论:2026年的正确答案是”混合架构,边缘优先”
半导体工厂的AI部署,没有简单的非此即彼。但如果必须给出一个优先级排序,答案非常清晰:边缘优先,云端赋能。
对于实时控制类应用(FDC、VM、R2R),边缘AI是唯一可行的选择,云端根本无法满足延迟和安全要求。对于分析优化类应用(跨站点良率分析、模型训练、数字孪生),云端有不可替代的优势。混合架构将两者的优势结合,是当前技术条件下的最优解。
NeuroBox E3200S的设计哲学,正是将最苛刻的实时推理能力沉到设备旁的边缘节点,将工艺数据的控制权还给工厂,同时通过云端协同实现模型持续进化。这不仅是一种技术架构,更是对半导体制造主权的坚守。
如果您正在评估产线AI部署方案,或者希望了解NeuroBox E3200S的详细技术规格和部署方案,欢迎联系迈烁集芯(MST)技术团队获取针对您产线的定制化分析报告。
读完这篇,下一步可以很具体
获取一份产线 AI 评估,看看 NeuroBox E3200 / SECS/GEM 怎么接到您的设备。
把设备类型、当前数据接口、工艺目标或良率问题发给我们。工程团队会先判断适合 VM、R2R、Smart DOE、EIP 还是能源优化,再给出下一步建议。
- 适合晶圆厂、设备商、工艺/设备/自动化团队
- 可从 SECS/GEM、Modbus、PLC、CSV/历史数据开始
- 不需要先提交机密 recipe 或客户图纸

